SPSS数据分析工具介绍
了解组距分组的基本概念
在变量值较多的情况下,通常采用组距分组的方法进行数据整理。该方法通过将全部变量值划分为若干个区间来实现数据的归类管理。其中涉及两个关键问题:一是如何确定合理的分组数量,二是如何计算每个组的组距。
如何确定合适的分组数量
分组数量应依据数据本身的特性及样本总量而定。理想的组数应当能够清晰展示数据分布规律。如果组数过少会导致信息集中难以区分,而过多则会使数据过于分散。推荐使用Sturges公式作为参考来确定最佳分组数目。
组距的计算方法
组距指的是每组上限与下限之间的差值。具体计算时,可先确定最大值和最小值之差,然后除以预设的组数,从而得出组距。
实际操作演示
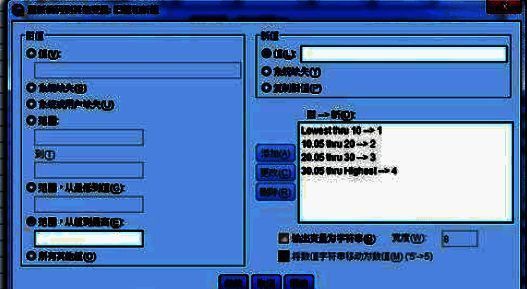
接下来将以分成4组为例,详细介绍SPSS中数据分组的具体步骤。首先调出“旧值和新值”设置界面,在这里可以定义从旧数值到新组别的映射规则。
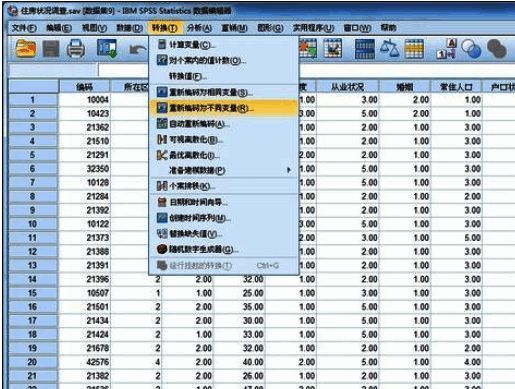
设定新的变量组别规则
例如,将旧值中的最小数至10的数值归为一组,并将其标记为1。记得每次添加新规则后点击“添加”按钮确认更改。其他组别的设定遵循相同逻辑。
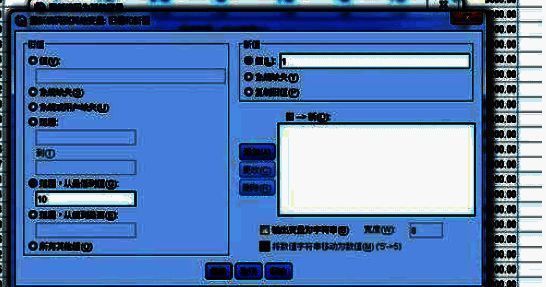
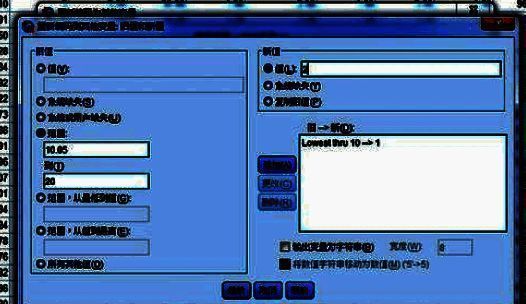
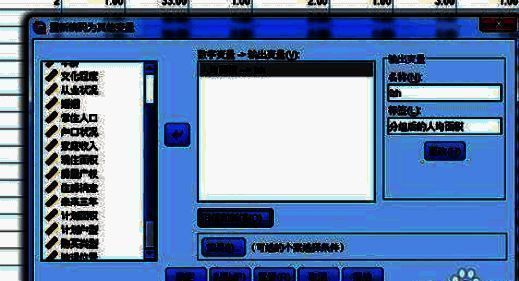
定义输出变量名称
在“输出变量”部分,需要为新生成的分类变量指定一个名称及其标签,以便后续分析时识别这些变量。
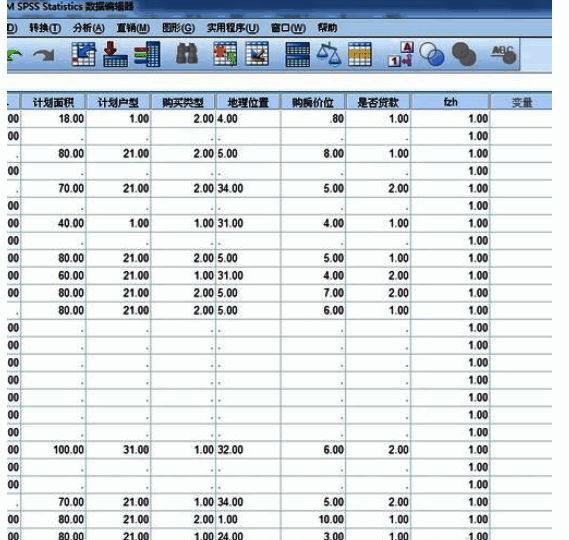
查看最终分组结果
完成所有设置之后,可以在数据视图中看到新增的分类变量列,比如命名为“fzh”的变量即表示此次分组的结果。以下图片展示了第一组的部分数据情况。